SubstrateVM, the native image AOT compiler from GraalVM, is one of the hot topics for the java community in the last couple of months. Everyone is excited with small binaries, low resource consumption it brings to the java ecosystem, but is it all true?
I’ve blogged before about native images and how cool they are for serverless, what I haven’t done is blog about using it for performance/cpu intensive applications.
Many people will make the wrong assumption that just because native images are small and compact both on disk space and memory usage they are high performance pieces of software, but lets look at this premise and do some proper research. As you should already know Eclipse Vert.x does work with almost no pain with native images, also, it is one of the fastest low-latency frameworks out there as verified by TechEmpower benchmarks. So let’s look what to expect once you go native.
Setup
First of all, let’s start with the basic benchmark code, you can read all about the official requirements here.
For this example I’ll be using the following dependencies:
io.vertx:vertx-core:3.6.0-SNAPSHOTio.vertx:vertx-web:3.6.0-SNAPSHOTio.reactiverse:reactive-pg-client:0.10.5
As usual we start with a verticle (TechEmpower.java):
public class TechEmpower extends AbstractVerticle {
private final String server = "vertx";
private String date;
@Override
public void start() {
// will route http paths to benchmark implementations
final Router app = Router.router(vertx);
// generate the required value for the date header
vertx.setPeriodic(1000, handler -> date =
DateTimeFormatter.RFC_1123_DATE_TIME.format(ZonedDateTime.now()));
// the postgres client to perform data related operations
// as required by the benchmark
PgClient client = PgClient.pool(
vertx,
new PgPoolOptions()
.setUser("benchmarkdbuser")
.setPassword("benchmarkdbpass")
.setDatabase("hello_world"));
// TODO: implement benchmark here...
// create an HTTP server and bind to a specific port
vertx
.createHttpServer()
.requestHandler(app)
.listen(8080);
}
}
Now that we have the boilerplate code in place it is time to add the benchmarks, since I’m not adding a template engine I’ll just implement part of the benchmark, so the code stays small and it is easy to follow, as an exercise you can implement the missing parts.
JSON benchmark
According to the requirements:
This test exercises the framework fundamentals including keep-alive support, request routing, request header parsing, object instantiation, JSON serialization, response header generation, and request count throughput.
app.get("/json").handler(ctx -> {
ctx.response()
.putHeader("Server", server)
.putHeader("Date", date)
.putHeader("Content-Type", "application/json")
.end(new JsonObject().put("message", "Hello, World!").toBuffer());
});
Data Access benchmark
According to the requirements:
This test exercises the framework’s object-relational mapper (ORM), random number generator, database driver, and database connection pool.
app.get("/db").handler(ctx -> {
client.preparedQuery(
"SELECT id, randomnumber from WORLD where id=$1",
Tuple.of(randomWorld()),
res -> {
if (res.succeeded()) {
PgIterator resultSet = res.result().iterator();
if (!resultSet.hasNext()) {
ctx.fail(404);
return;
}
Row row = resultSet.next();
ctx.response()
.putHeader("Server", server)
.putHeader("Date", date)
.putHeader("Content-Type", "application/json")
.end(new JsonObject()
.put("id", row.getInteger(0))
.put("randomNumber", row.getInteger(1))
.toBuffer());
} else {
ctx.fail(res.cause());
}
});
});
Multiple Queries benchmark
According to the requirements:
This test is a variation of Test #2 and also uses the World table. Multiple rows are fetched to more dramatically punish the database driver and connection pool. At the highest queries-per-request tested (20), this test demonstrates all frameworks’ convergence toward zero requests-per-second as database activity increases.
app.get("/queries").handler(ctx -> {
final AtomicBoolean failed = new AtomicBoolean(false);
JsonArray worlds = new JsonArray();
final int queries = getQueries(ctx.request());
for (int i = 0; i < queries; i++) {
client.preparedQuery(
"SELECT id, randomnumber from WORLD where id=$1",
Tuple.of(randomWorld()),
ar -> {
if (!failed.get()) {
if (ar.failed()) {
failed.set(true);
ctx.fail(ar.cause());
return;
}
// we need a final reference
final Row row = ar.result().iterator().next();
worlds.add(new JsonObject()
.put("id", row.getInteger(0))
.put("randomNumber", row.getInteger(1)));
// stop condition
if (worlds.size() == queries) {
ctx.response()
.putHeader("Server", server)
.putHeader("Date", date)
.putHeader("Content-Type", "application/json")
.end(worlds.toBuffer());
}
}
});
}
});
Plaintext benchmark
According to the requirements:
This test is an exercise of the request-routing fundamentals only, designed to demonstrate the capacity of high-performance platforms in particular. Requests will be sent using HTTP pipelining. The response payload is still small, meaning good performance is still necessary in order to saturate the gigabit Ethernet of the test environment.
app.get("/plaintext").handler(ctx -> {
ctx.response()
.putHeader("Server", server)
.putHeader("Date", date)
.putHeader("Content-Type", "text/plain")
.end("Hello, World!");
});
Running the benchmark
When we run the benchmark, in order to take full advantage of the hardware and try to reduce any potential locking we will spawn the same number of CPU cores instances of the verticle. For this we run the following command:
java
-server
-XX:+UseNUMA
-XX:+UseParallelGC
-XX:+AggressiveOpts
-Dvertx.disableMetrics=true
-Dvertx.disableH2c=true
-Dvertx.disableWebsockets=true
-Dvertx.flashPolicyHandler=false
-Dvertx.threadChecks=false
-Dvertx.disableContextTimings=true
-Dvertx.disableTCCL=true
-jar target/benchmark-0.0.1-SNAPSHOT-fat.jar
--instances `grep --count ^processor /proc/cpuinfo`
Now since native images require a proper main, we can add the following main to the code:
public static void main(String[] args) {
int instances = 1;
for (int i = 0; i < args.length; i++) {
String arg = args[i];
if ("--instances".equals(arg)) {
instances = Integer.parseInt(args[i+1]);
}
}
final Vertx vertx = Vertx.vertx();
for (int i = 0; i < instances; i++) {
vertx.deployVerticle(new TechEmpower());
}
}
This will perform the same operation that the vert.x launcher would for the only non JVM specific argument --instances. This way we ensure the same conditions and runtime code is the same in the native image and on the JVM counterpart. We finally build the image with:
native-image
--no-server
--enable-all-security-services
--delay-class-initialization-to-runtime=
io.netty.handler.codec.http.HttpObjectEncoder,
io.netty.handler.codec.http2.Http2CodecUtil,
io.netty.handler.codec.http2.DefaultHttp2FrameWriter,
io.netty.handler.codec.http.websocketx.WebSocket00FrameEncoder,
io.netty.handler.ssl.JdkNpnApplicationProtocolNegotiator,
io.netty.handler.ssl.ReferenceCountedOpenSslEngine
-Dvertx.disableDnsResolver=true
-H:+ReportUnsupportedElementsAtRuntime
-Dvertx.disableMetrics=true
-Dvertx.disableH2c=true
-Dvertx.disableWebsockets=true
-Dvertx.flashPolicyHandler=false
-Dvertx.threadChecks=false
-Dvertx.disableContextTimings=true
-Dvertx.disableTCCL=true
-jar target/benchmark-0.0.1-SNAPSHOT-fat.jar
As we can see we use the same parameters when initializing the native image heap and we run it as:
./target/benchmark-0.0.1-SNAPSHOT-fat
-Dvertx.disableMetrics=true
-Dvertx.disableH2c=true
-Dvertx.disableWebsockets=true
-Dvertx.flashPolicyHandler=false
-Dvertx.threadChecks=false
-Dvertx.disableContextTimings=true
-Dvertx.disableTCCL=true
--instances `grep --count ^processor /proc/cpuinfo`
Just to be sure the same flags are used.
Results
The results are probably what you’re not expecting, I’ve plotted 2 results for the sake of visualization, the JSON test and the data access test:
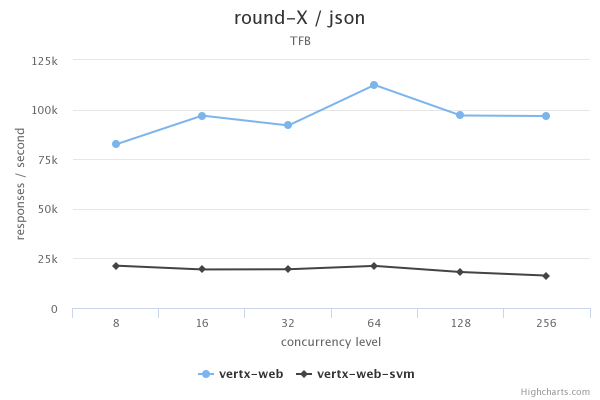
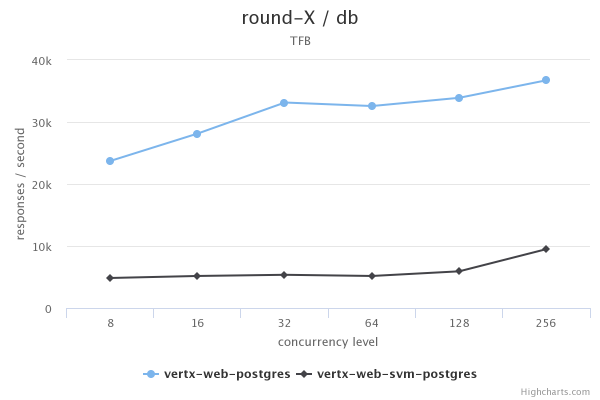
I must also note that the plaintext tests failed at the highest concurrency ONLY on the native image side with some unexcepted exceptions at the IO stack (however there are no errors when running on the JVM).
So what does this mean? To me, this shows that native images are a powerful feature from GraalVM but they are not the holy grail! Their use case is cli, serverless like applications (as the graal team also says) and they are not really suited (as things stand today) for high performance, long running processes.